



【AZ-900】Azure Service Health(サービス正常性)とは?Resource Health(リソース正常性)との違いも解説!

どうも、フリーランスエンジニアのMakotoです。
今回は、Azure Service Healthについて解説します。
Azureにはサービスやリソースが正しく動作しているか確認する方法がいくつかありますが、その手段によってカバーする範囲が異なっていたります。
自社で利用しているリージョン、サービス、リソースへの影響を知るためにはその違いを理解することが重要ですので、ぜひ、最後までお読みください。
それではいってみましょう!
Azure Service Healthとは?
Azure Service Healthは、Azureの障害や計画的メンテナンス、その他可用性に影響する可能性のある変更などを把握するためのサービスで、次の3つのサービスがあります。
- Azureの状態
- Service Health(サービス正常性)
- Resource Health(リソース正常性)

はい、そうなんです。ひじょーに紛らわしいです。笑
ただ、AZ-900試験の対策としては「Service Health(サービス正常性)」の内容をおさえておけば良さそうです。(あくまで私の個人的な感想です)
実際、書籍などではAzure Service Health = Service Health(サービス正常性)として扱われている場合もありますが、公式ドキュメントではAzure Service Healthという親サービスの中に3つの子サービスがある、といった位置づけで記載されています。
AZ-900試験の対策としては「Service Health(サービス正常性)」の内容が重要だと考えていますが、実務では3つのサービスそれぞれの用途と違いを知ることが重要です。
Azureの状態
Azureの状態では、リージョンごとのAzureサービスの稼働状況を表形式で確認することができます。Azureポータルとは別で提供されており、azure.status.microsoft からアクセスすることができます。
日本の利用者であれば多くの場合は「アジア太平洋」を選択して東日本・西日本の列をチェックすることになるでしょう。
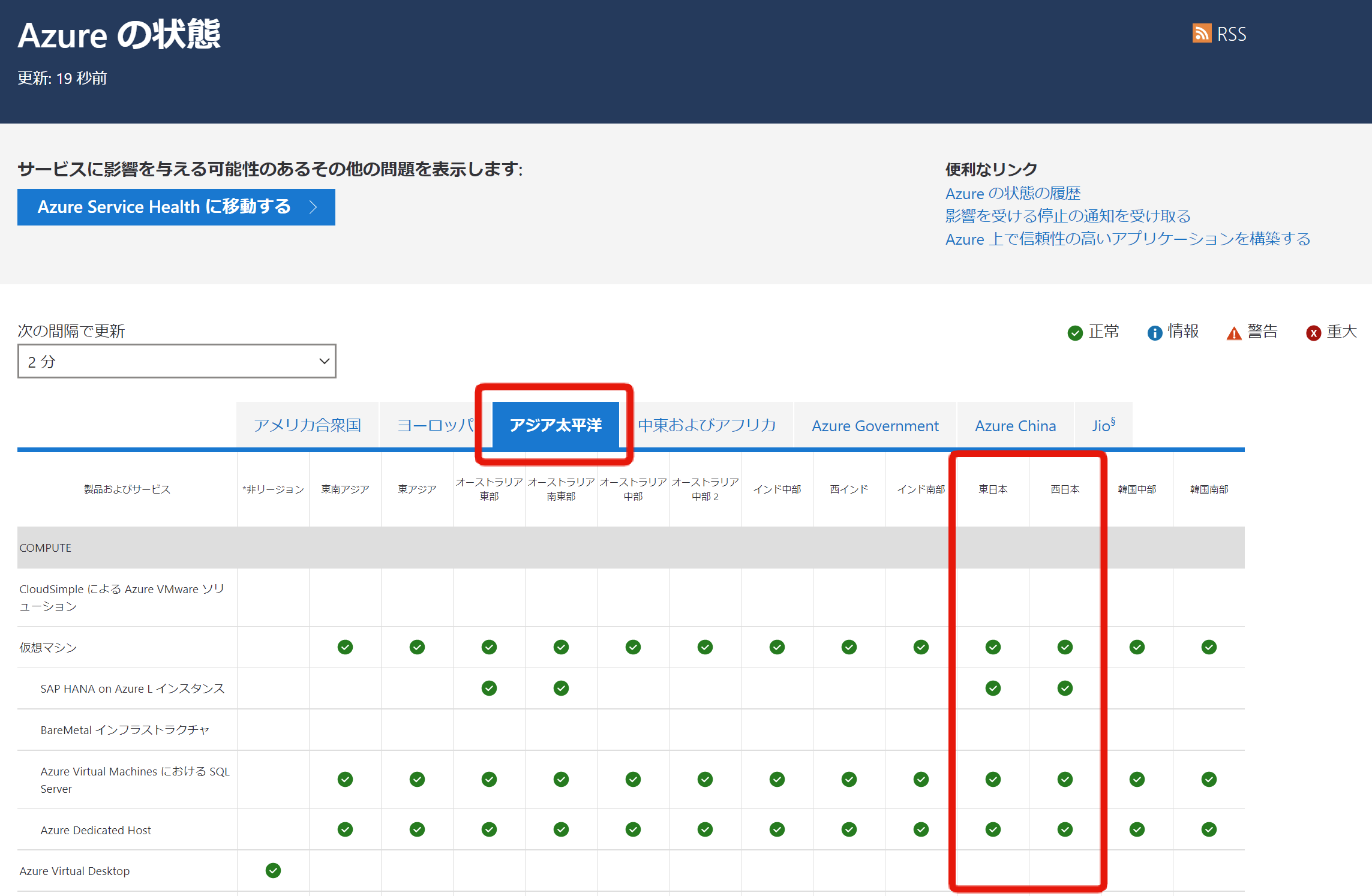
これは簡易的なツールの位置づけで、網羅的にひと目で確認できる反面、利用者に最適化されて必要な情報だけが表示されるわけではありませんし、アラート通知するような機能もありません。
Microsoftとしても後述する「Service Health(サービス正常性)」の利用を推奨しているようです。
Azureポータルにサインインできない場合や、Service Health(サービス正常性)にアクセスできないような場合にステータスをチェックする方法として覚えておきましょう。
Service Health(サービス正常性)
Service Healthは、Azureの状態と同様、Azureサービスが正しく動作しているかどうかを知るためのサービスです。「サービス正常性」とも呼ばれます。
リージョン規模の障害など大規模な障害があった場合に利用者がダッシュボードから確認したり、アラートルールを登録しておくことで通知を受け取ることができます。
障害のみならず、次の4つに分類されたイベントを確認・追跡できます。
| イベントの種類 | 説明 |
|---|---|
| サービスに関する問題 | 即座に影響のあるAzureサービスの問題(障害) |
| 計画メンテナンス | 可用性に影響する可能性がある将来のメンテナンス |
| 正常性の勧告 | Azureの機能の変更点(ある機能が非推奨になるなど) |
| セキュリティアドバイザリ | 可用性に影響する可能性があるセキュリティ関連の通知や違反 |
Azureポータルを見ると4つのカテゴリごとに用意されているメニューからイベントを確認できることがわかります。
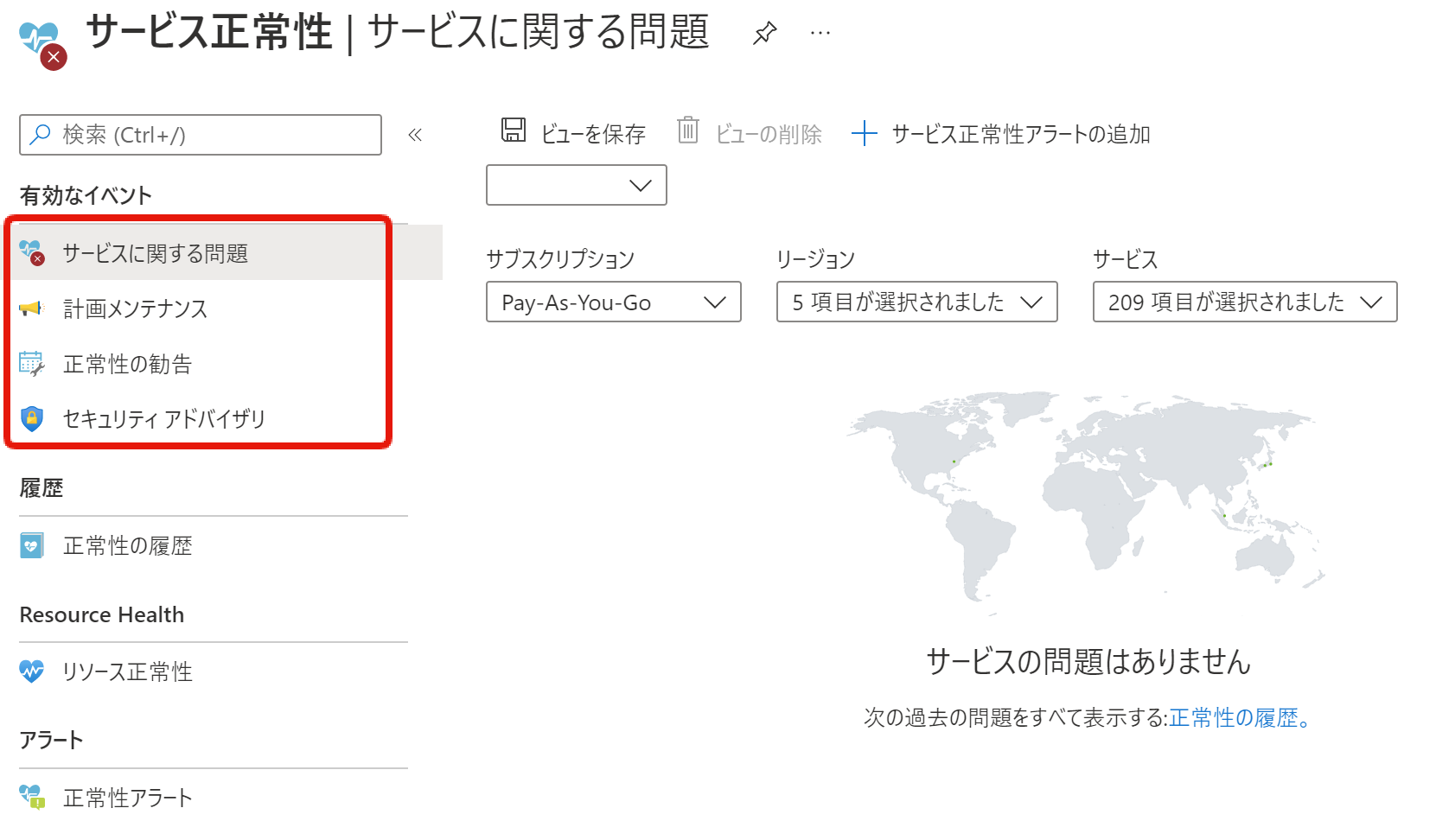
ユーザーが利用中のリージョンのみが選択された状態に最適化されていますが、個別にリージョンやサービスをプルダウンから選択して条件を変えて確認することもできます。
AZ-900試験の対策としては特に「サービスに関する問題」と「計画メンテナンス」を知るための手段である点をおさえておきましょう。
「サービス正常性アラートの追加」を押すとアラートルールを作成して通知を送ることもできます。
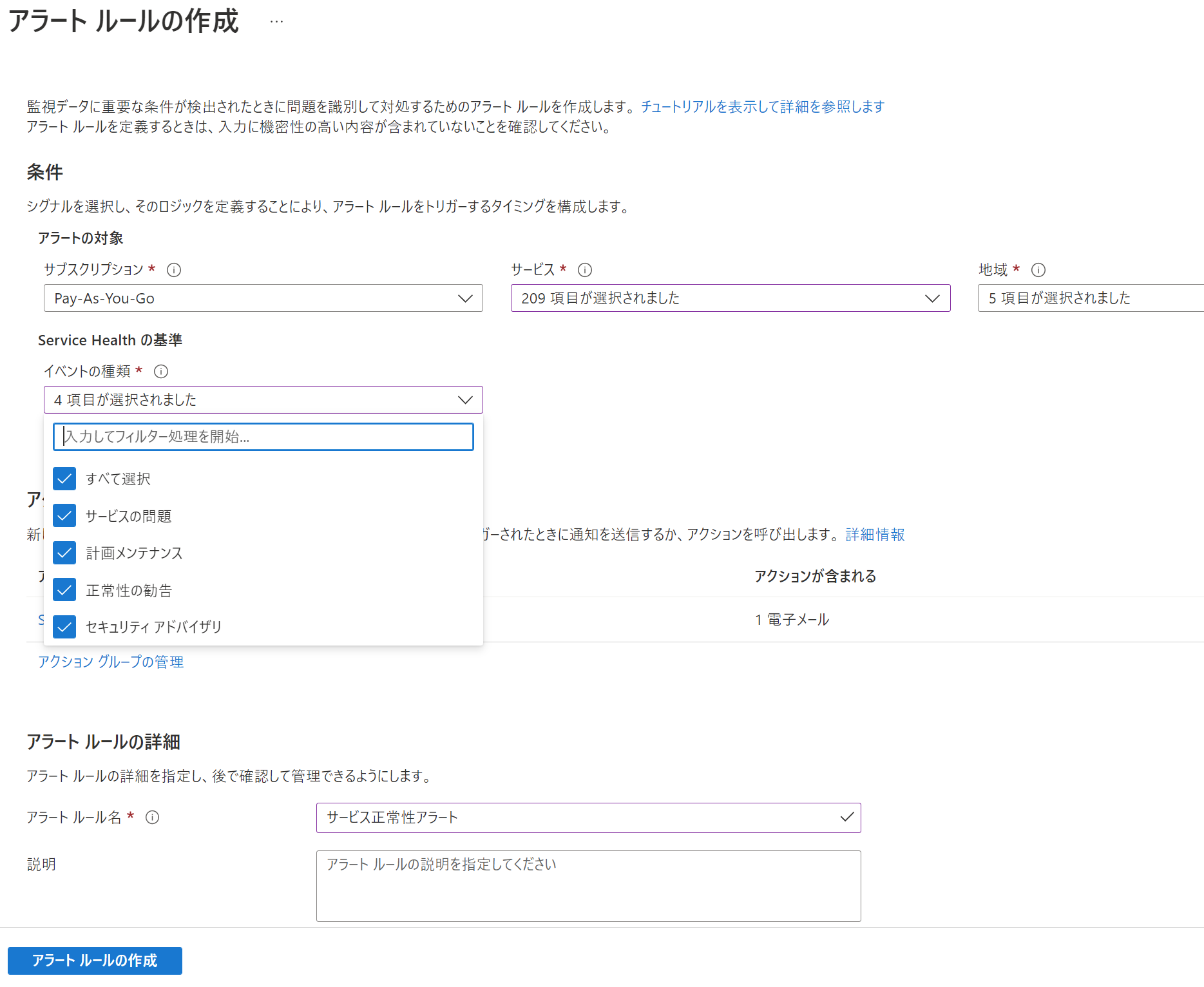
デフォルトでは「地域(リージョン)」「サービス」がすべて選択された状態になるため、利用していないリージョン、サービスを除外する必要があるように思えますが、利用しているサービスの利用しているリージョンを対象としたイベントが発生した場合にのみ通知が行われる仕組みのため、どちらとも「すべて選択」することが推奨されています。
サービス正常性アラートの推奨設定については以下のブログ記事を参考にしてください。
Resource Health(リソース正常性)
Resource Healthは、仮想マシンなどリソース単位で状態を確認したり過去に発生した障害について確認することができます。「リソース正常性」とも呼ばれます。
リソース正常性のメニューを開き、リソースの種類を選択後、対象のリソース名を選択すると状態を確認することができます(一覧表示の時点で緑のチェックマークは付いていますね)
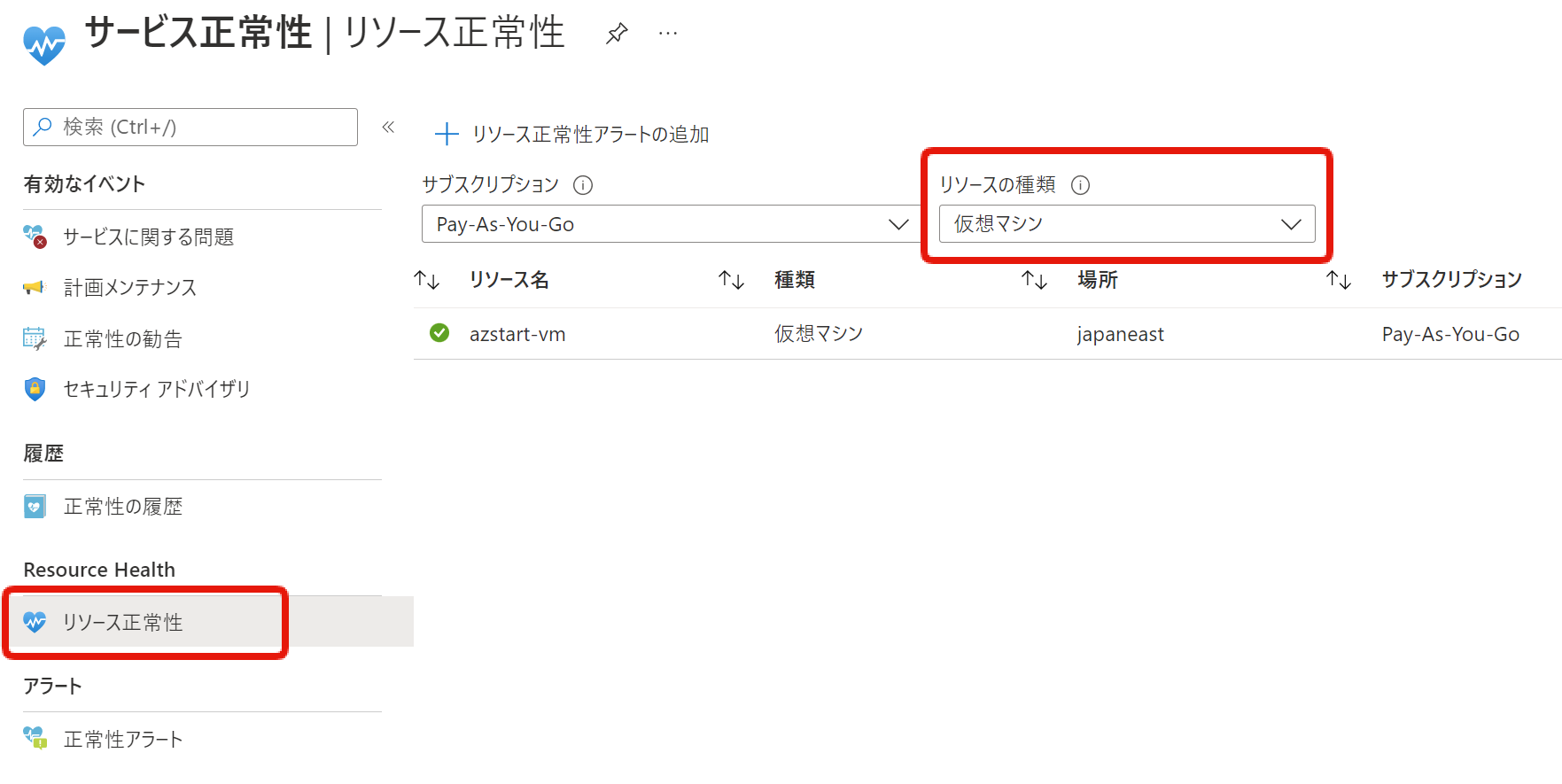 現在の状態が「利用可能」であることがわかります。
現在の状態が「利用可能」であることがわかります。
「正常性の履歴」からは最大30日間の履歴を確認できますが、このサンプル画面では停止していたVMを起動しただけなので履歴が貯まっていません。。
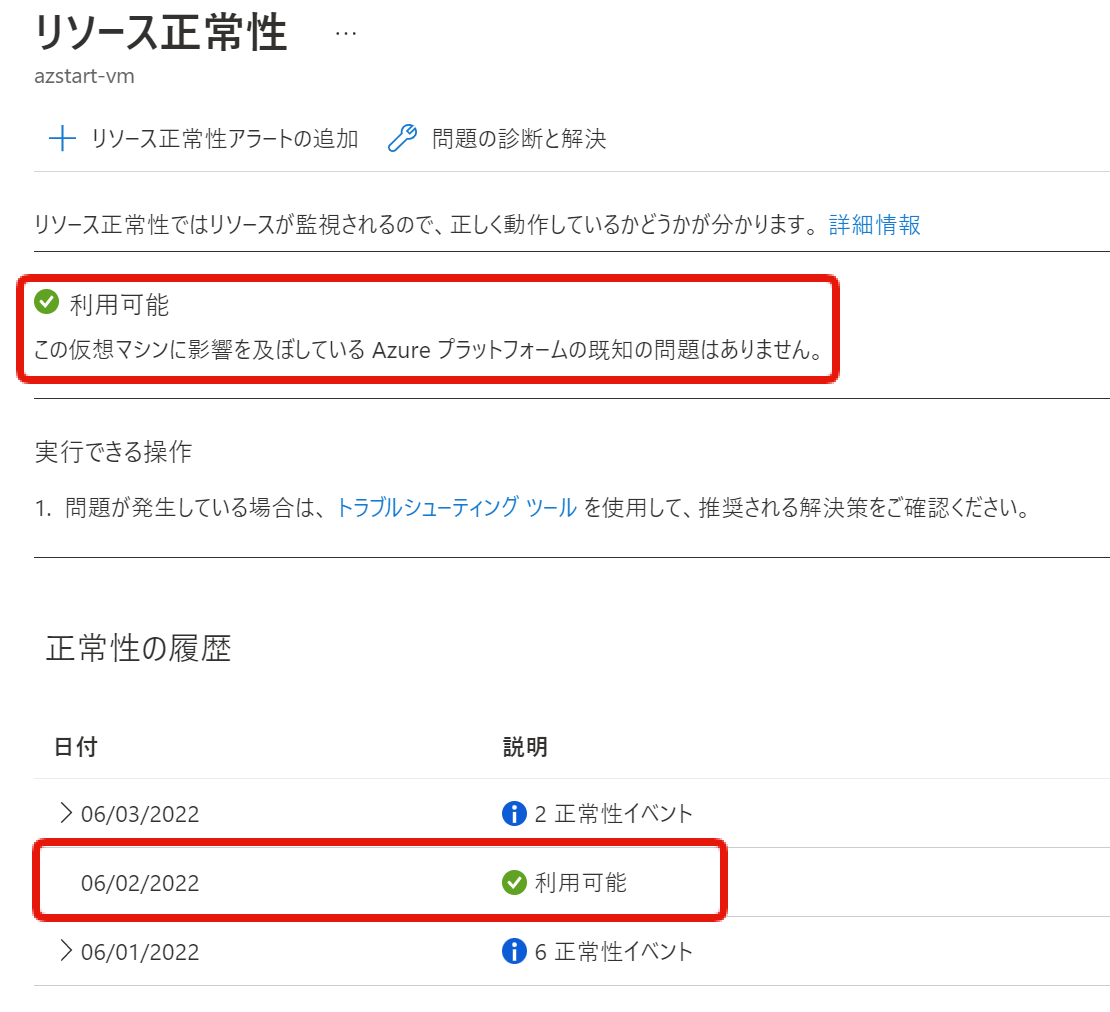
仮想マシンのメニューの中にある「リソース正常性」からも同じ内容を確認することができます。
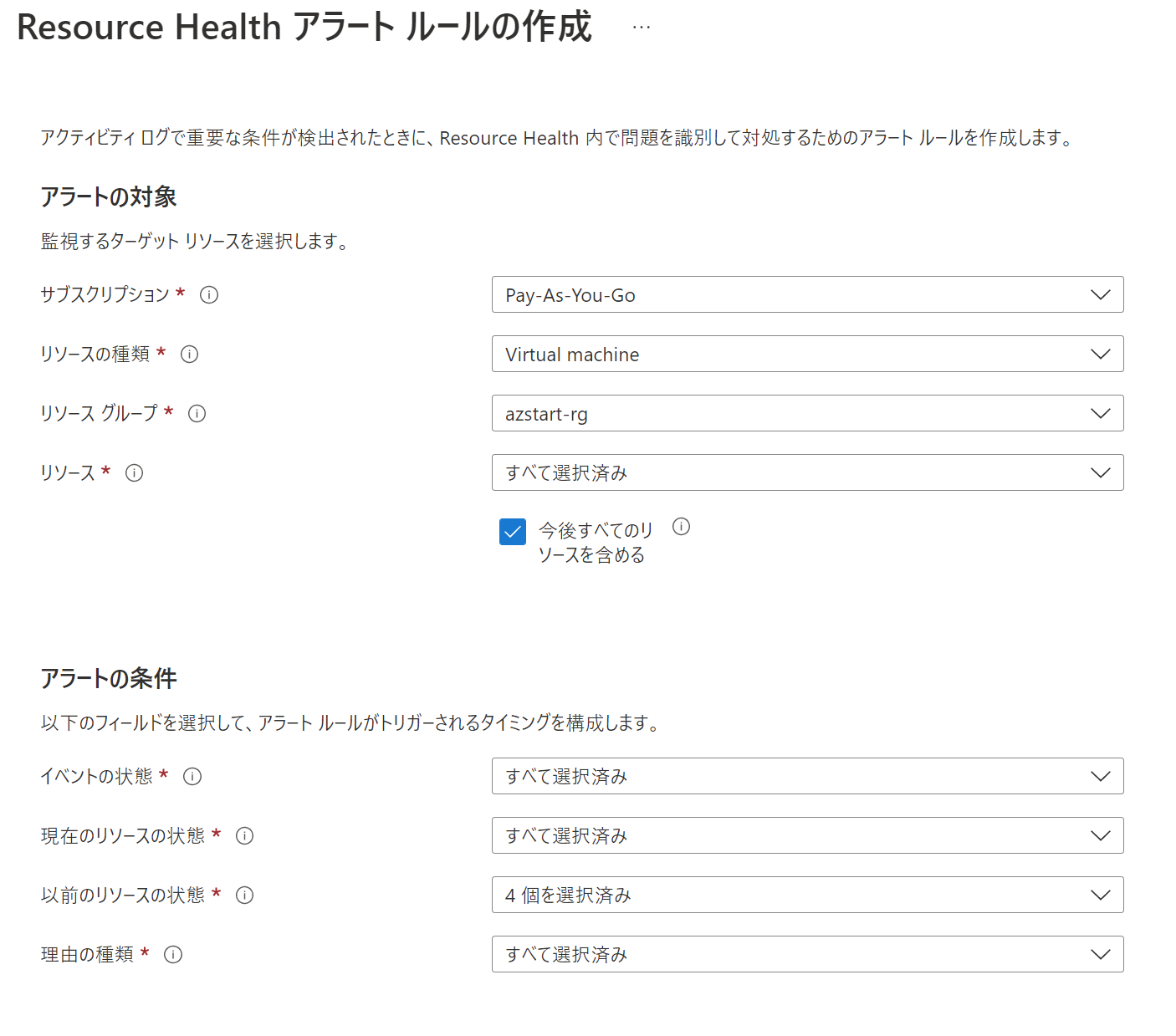
サービス正常性と同じように「リソース正常性アラートの追加」を押すとアラートルールを作成して通知を送ることもできます。
リソース正常性は全てのサービスがサポートされているわけではありません。
サポートされているリソースの種類の一覧と正常性チェックの内容は公式ドキュメントを参照してください。
サービス正常性とリソース正常性の違い
さて、ここまでの内容を読んで多くの人はこう思うかもしれません。

公式ドキュメントのFAQには次のように書かれています。
Service Health と Resource Health の違いは何ですか?
Resource Health では、特定の仮想マシン インスタンスなど、個々のクラウド リソースの正常性に関する情報を入手できます。Service Health は、Azure のサービスとリージョンの状態、現在のインシデント、計画メンテナンス、正常性の勧告に関する情報をパーソナライズして提供します。
改めて書きますが名前にもあるように、
- Resource Health → リソース
- Service Health → サービス
に関する正常性を確認する方法です。
例えば、東日本リージョンで仮想マシンを利用しているとしましょう。障害を検知したいシーンを想定します。
経験上よくあるのですが、仮想マシンをホストしている物理マシンに障害があったりディスク劣化による障害予兆が検知された場合、サービス正常性では気付くことができません。
サービス正常性は、サービス全体に影響を及ぼすような大規模な障害に対して通知を行いますが、部分的なラック単位での障害などの場合は通知されません。
逆に言うと、東日本リージョンで大規模な障害があった場合、両方のアラートルールを設定していればどちらとも通知が送られてくることになると思います。
つまり、どちらとも重要です。
大規模な障害はめったにないですが、計画メンテナンスやその他のAzureサービスの変更を知るために「サービス正常性」が役立ちます。
そして、仮想マシンなど個々のリソース単位で正常に稼働しているか点検するためには「リソース正常性」が便利です。
なので、ほとんどの場合、セットで利用するべきサービスと言えるでしょう。
まとめ
今回はAzure Service Healthについて解説しました。
正常性を確認する画面自体はわりとシンプルでわかりやすいのですが、いざ自分の環境にあった使い方をしようとすると3つのサービスの使い分けや設定に迷うかかもしれません。
3つのサービスを簡単にまとめると次のようになります。まずはそれぞれの用途と違いをしっかり理解しておきましょう。
| サービス | 範囲 | 利用者ごとに最適化 ※ |
|---|---|---|
| Azureの状態 | リージョンごとのサービス | × |
| Service Health(サービス正常性) | リージョンごとのサービス | 〇 |
| Resource Health(リソース正常性) | リソース単位 | 〇 |
※「利用者ごとに最適化」は公式ドキュメントでは「パーソナライズ」と表記されています
繰り返しになりますが、実務では3つのサービスそれぞれの用途と違いを知ることが重要ですが、AZ-900試験の対策としては恐らく「Service Health(サービス正常性)」の内容が問われやすいと思われます。
それでは、また。














