



【AZ-900】What is Azure Storage? Complete Guide to Data Services and Redundancy Options

Hi, I’m Makoto, a freelance engineer.
In this article, I’ll explain the storage services provided by Azure.
For those who are new to cloud computing, I feel that this storage service introduces many unfamiliar terms.

You may feel this way.
That’s probably because you’re not familiar with storage uses other than the disks on your everyday computer or file servers. Besides, there are many options…
In this article, I’ll explain everything in an easy-to-understand way using diagrams and screenshots from the Azure portal, so please read to the end.
Let’s get started!
What is Azure Storage?
Azure Storage is a service that provides storage for saving data and is classified as IaaS.
It provides high durability, scalability, and security with cloud-specific features. For example, it’s designed to provide eleven-nines (99.999999999%) or higher uptime, and stored data is automatically encrypted.
First, let’s get the big picture with the following diagram.
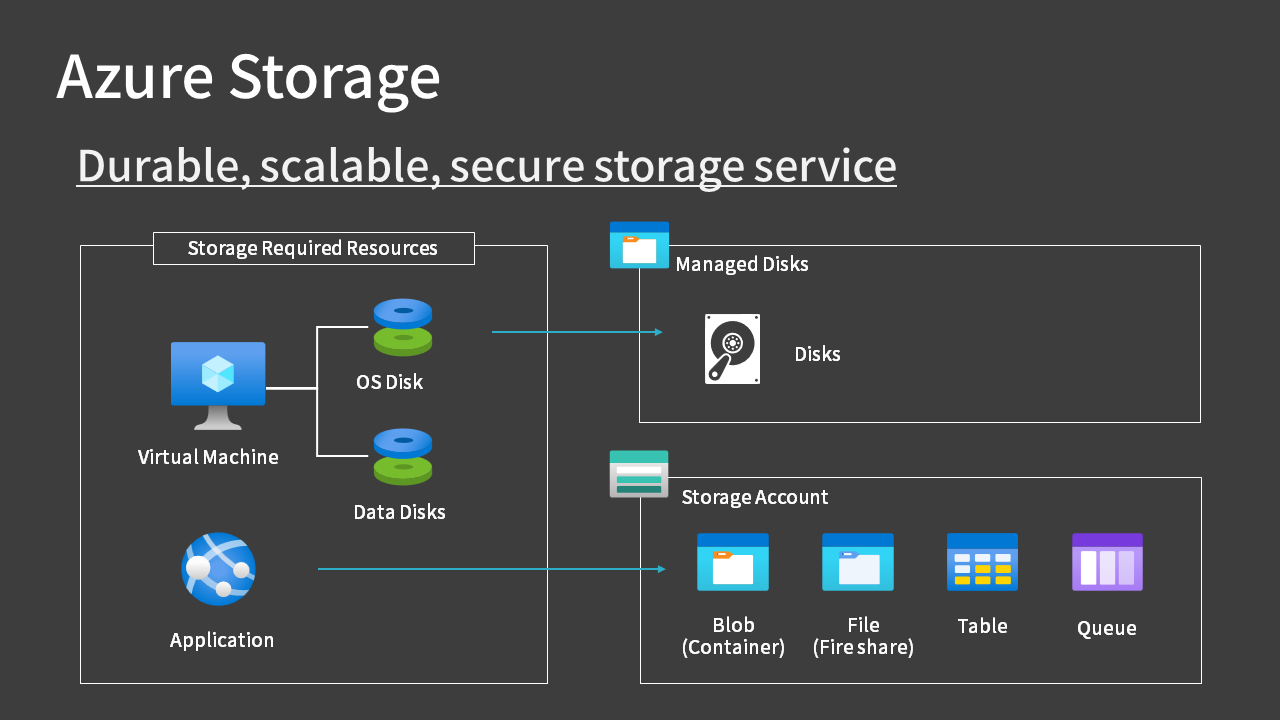
Azure Storage consists of two broad types:
- Managed disk, which provides disk for virtual machines
- Storage for applications to use as they see fit
The first, disks for virtual machines, is easier to imagine. OS disks and data disks are stored internally in Azure Storage “blob” storage and are managed by Azure, so you don’t have to worry about their location.
Because they’re managed by Azure, they’re called Managed Disks. For details, see this article.

For the latter, you can use four services by creating a resource called a Storage Account. The uses of these services will be explained later.
- Blob
- File
- Table
- Queue
When people talk about Azure Storage, they often refer to these four services that can be used by creating a storage account. This article will also explain the content related to storage accounts.
Reference:
There are five main types of Azure storage services: Blob, File, Table, Queue, and Disk. However, because disk storage (also known as managed disks) is exclusive to virtual machines, Azure Storage is often discussed in the context of the four types without disk storage.
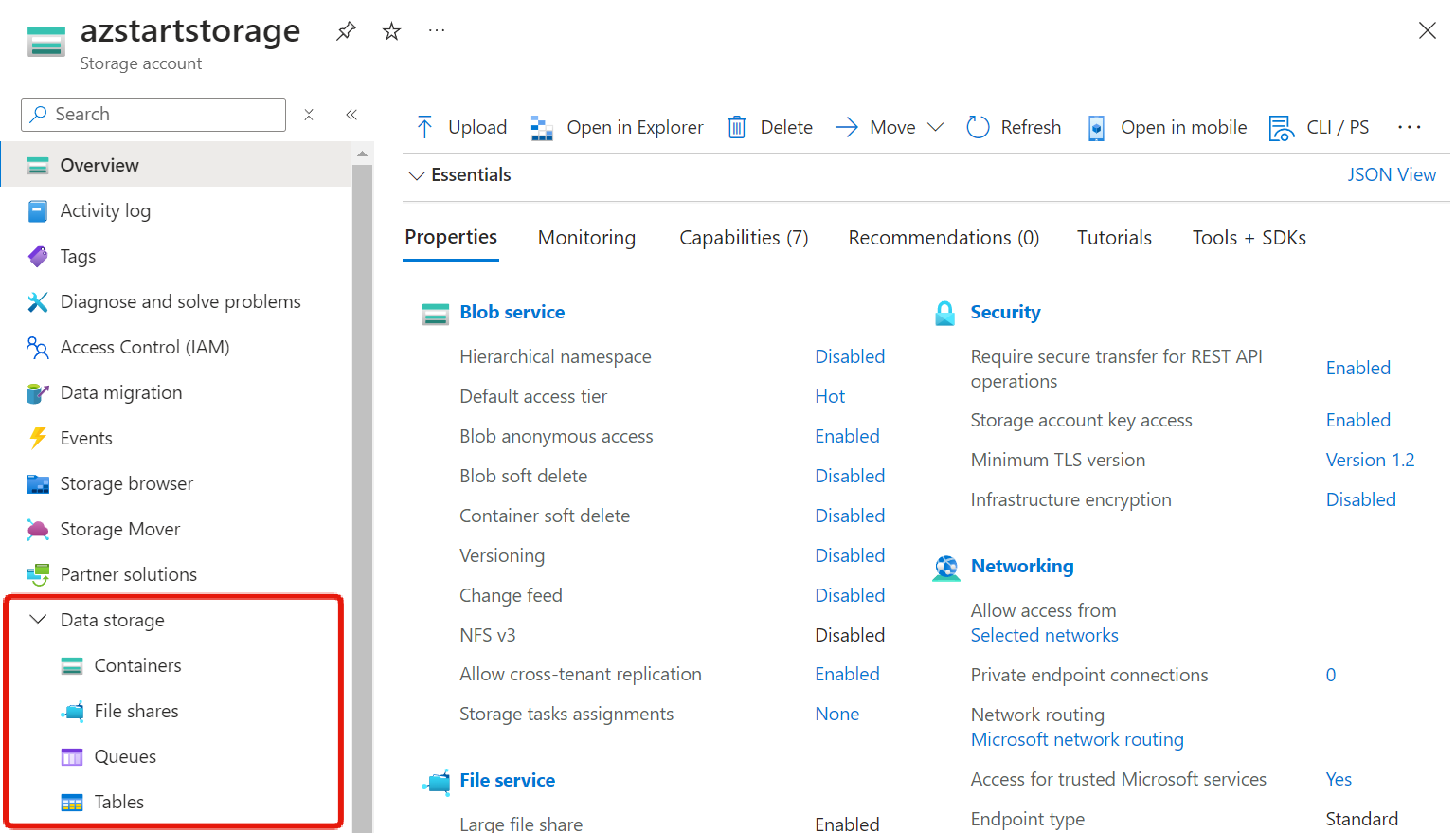
When you create a storage account, you will see four services listed as data storage. Note that “Containers” refers to Blob and “File shares” refers to File.
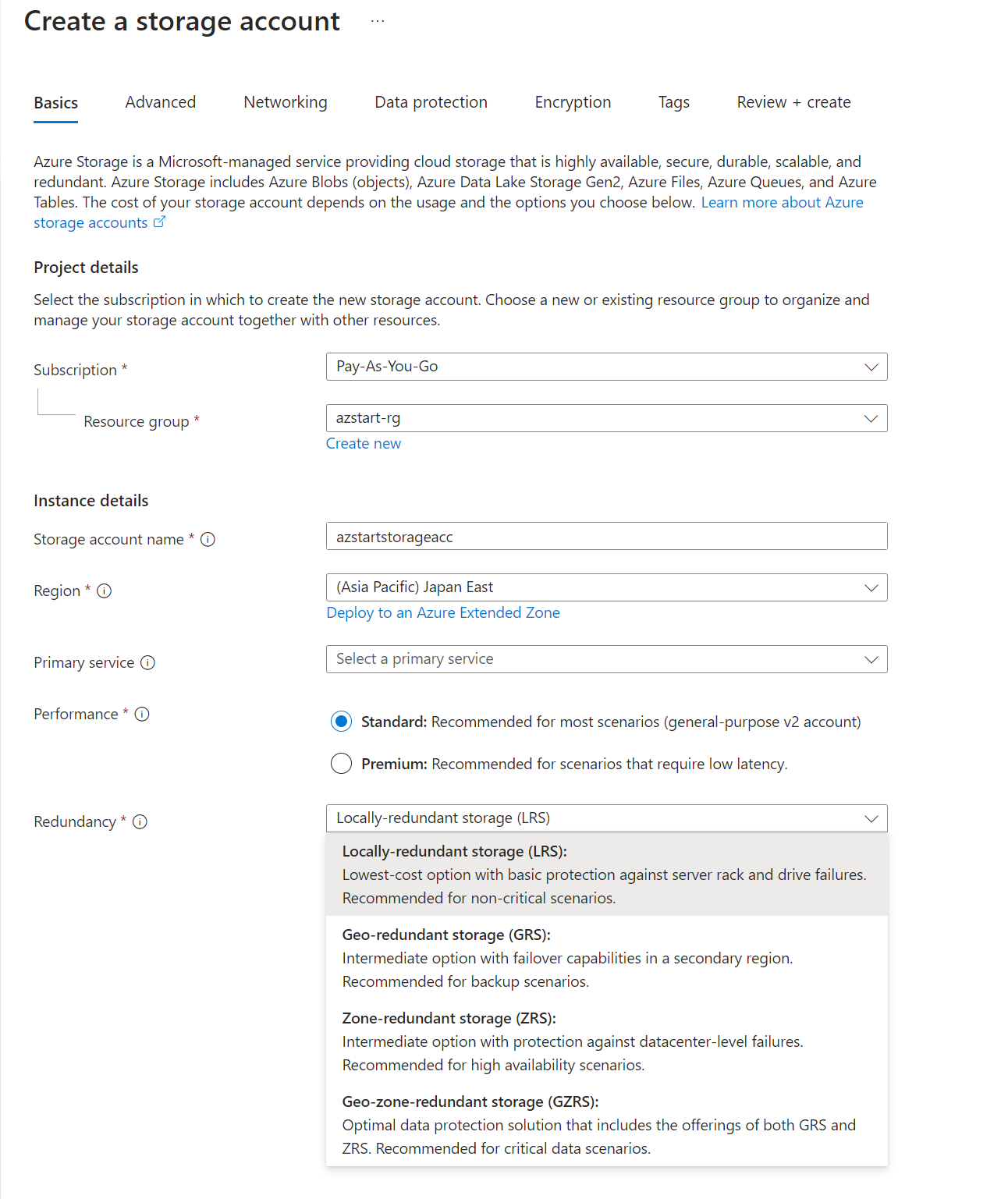
When you create a storage account, you specify the following items. Performance and redundancy will be discussed later.
- Storage account name
- 3 to 24 characters, lower case letters and numbers only. No symbols allowed
- Must be unique worldwide
- Region
- Performance
- Redundancy
Key Points:
To use Azure Storage, you need to create a storage account.
Reference:
By default, a storage account can store up to 5PiB of data, with no limit on the number of data items. For details, refer to Azure Storage limits.
Storage Account Performance
Storage accounts have two types of performance:
| Type | Use |
|---|---|
| Standard (general-purpose) | Recommended for most general scenarios |
| Premium | For systems requiring low latency |
In addition, Standard has two types, v1 and v2, with v2 being the newer service.
v1 is a legacy account type, while v2 can use the latest features and is more cost-optimized than v1.
For AZ-900 exam preparation, you probably don’t need to worry too much about the differences between v1 and v2 versions. It’s unlikely that legacy options will be asked about.
Currently, when we talk about storage accounts, “General-purpose v2 accounts” are the main option. If you select “Standard” in the Azure portal screen shown earlier, it will create a general-purpose v2 account. (v1 can no longer be created from the Azure portal)
Types of Data Services
As mentioned above, Azure Storage (storage account) has four services: Blob, File, Table, and Queue. Except for File storage, these are typically used by applications (programming code).
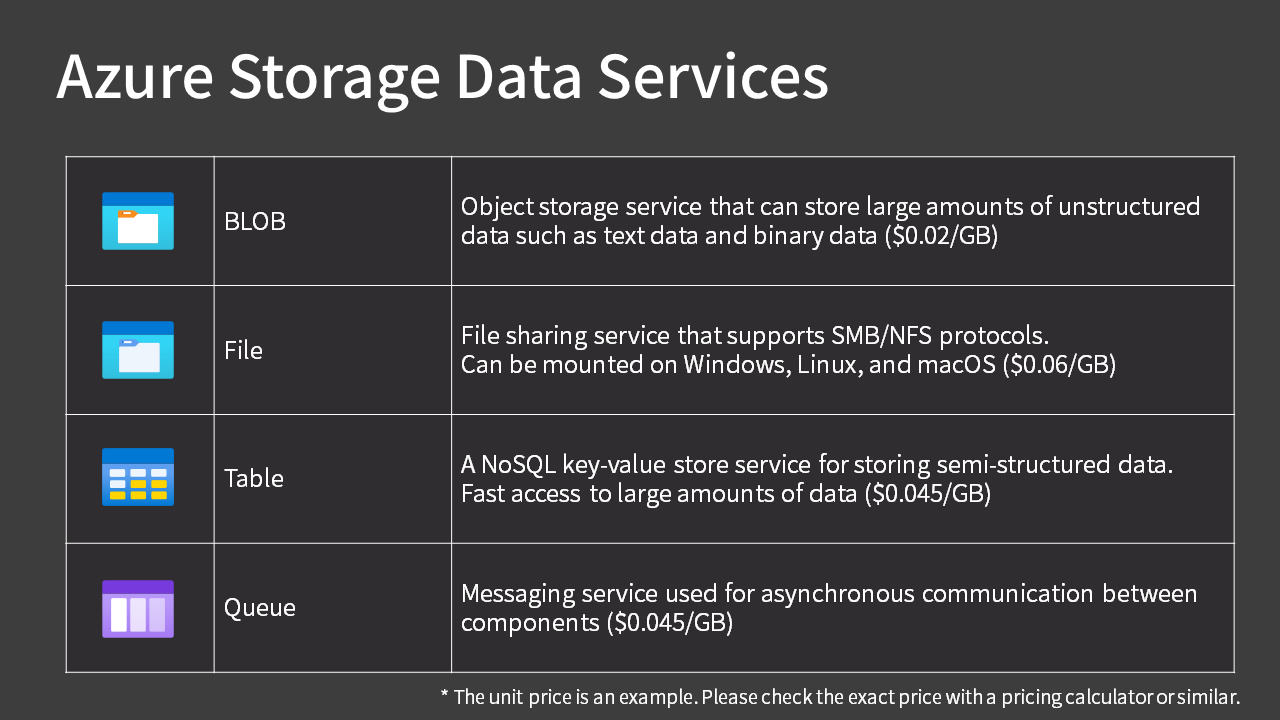
Blob
Blob storage is an object storage service that can store large amounts of unstructured data, such as text and binary data. It’s the equivalent of “S3” in AWS.
For example, it can be used to store video and audio files for streaming, or backup data that requires long-term storage.
One of its features is that it can be used inexpensively at about $0.02 per 1GB. Even storing 1TB would only cost about $21 per month.
What is Object Storage?
Object storage is a type of storage that manages data in units called objects. Unlike local disks on PCs, which use directory structures (paths) to manage storage locations, object storage uses identifiers called object IDs. Its flat, non-hierarchical structure makes it highly scalable and available.
The blob storage has the following structure:
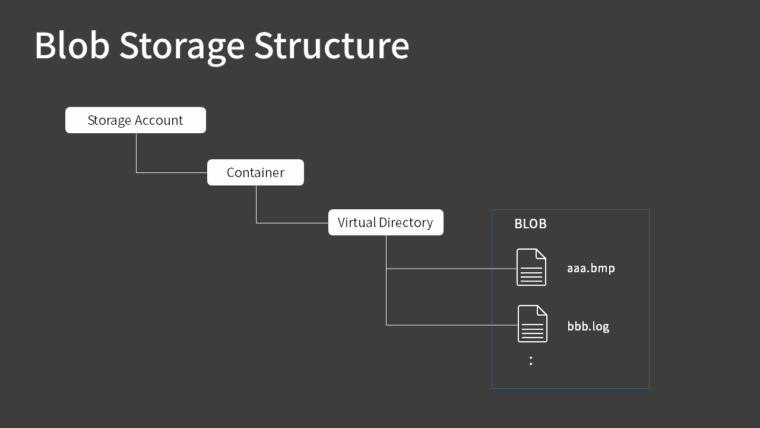
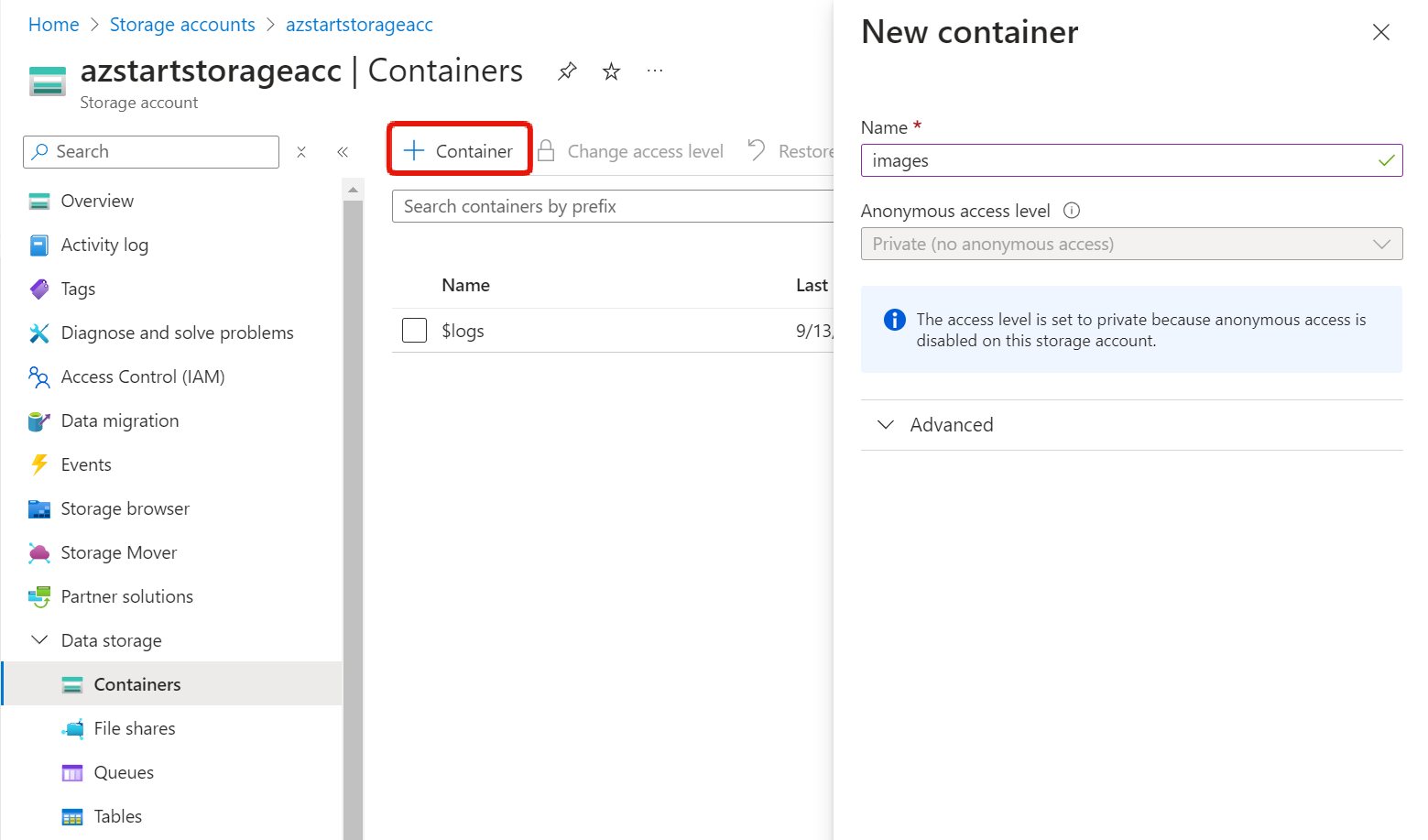
After you create a storage account, you create a container.
It’s like a root folder concept. In AWS terms, it’s the equivalent of a “bucket”.
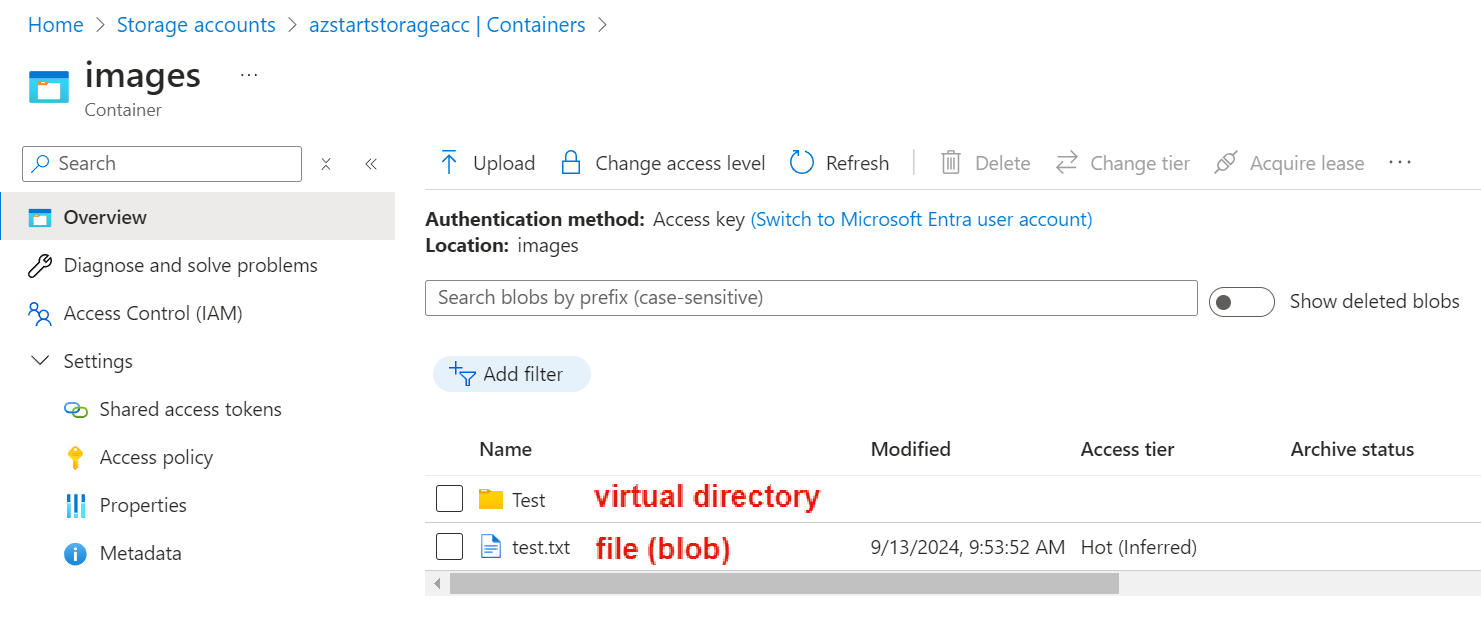
Once you’ve created a container, you can upload and store files in it. These files are called “blobs“. Although we mentioned that object storage doesn’t have a hierarchical structure, you can create a virtual directory to organize things in a hierarchical way for easier understanding.
File
File storage is a file sharing service that supports SMB/NFS protocols. It’s commonly used as a replacement for on-premises file servers. In AWS terms, it’s the equivalent of “EFS”.
It may be the most familiar service, but it may feel expensive, as it’s about 3 times the price of Blob.
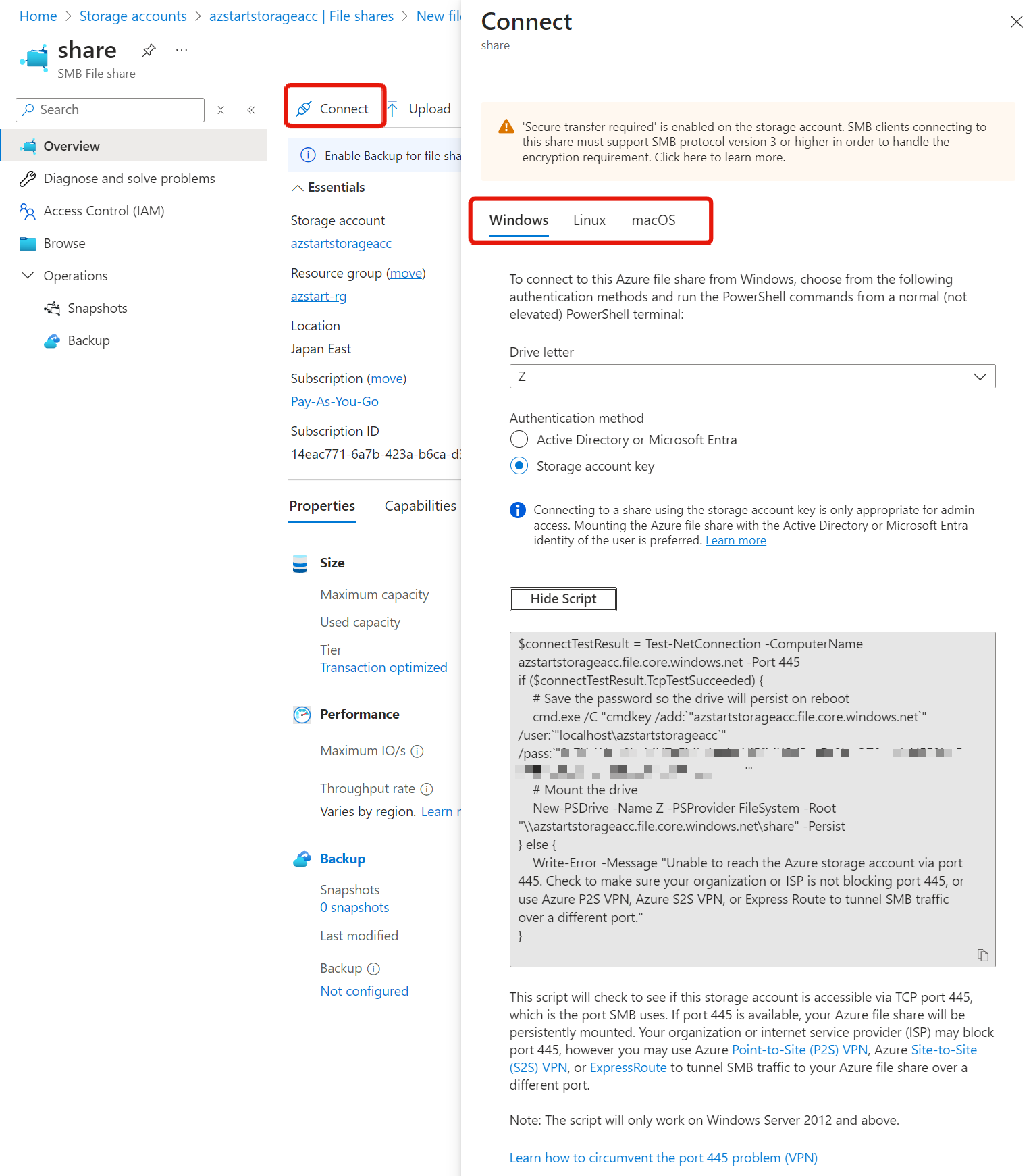
To use File, you create a “file share“, which is the equivalent of a shared folder. At this point, in addition to the name of the shared folder, you select a “level (access tier)“, which is an element of performance and price (explained later).
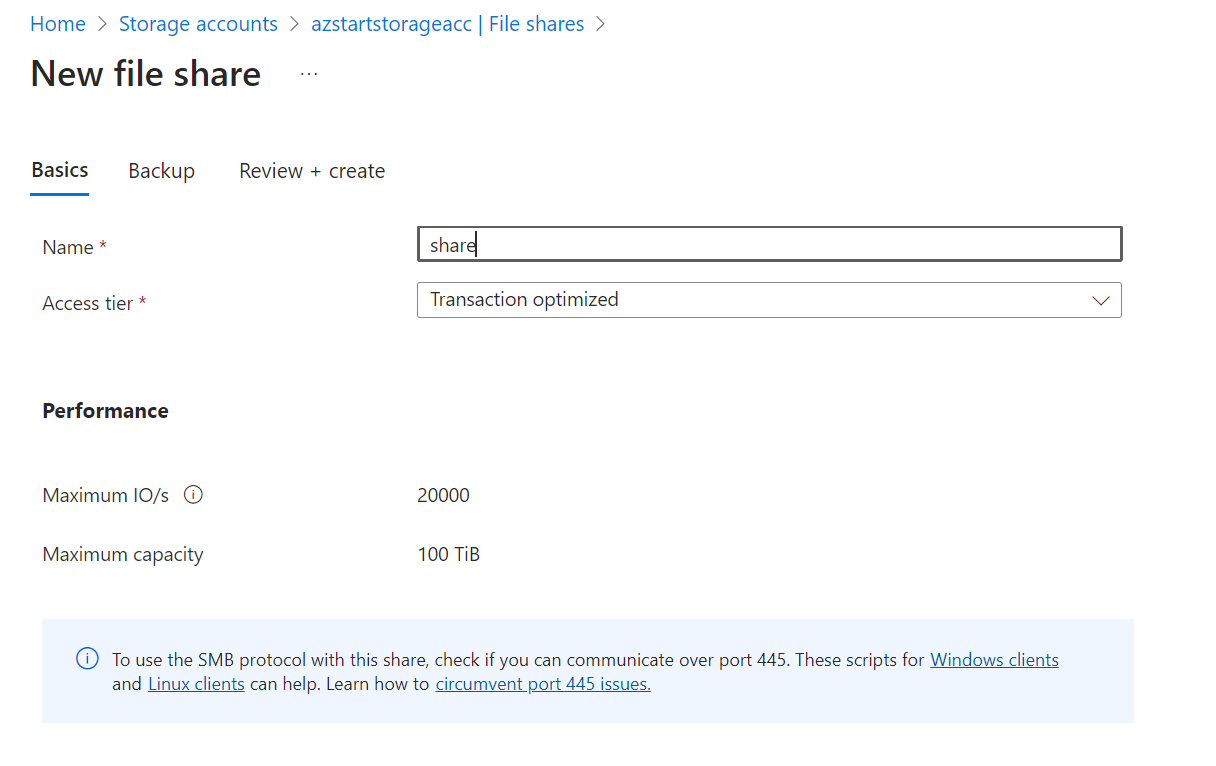
Once you have created a file share, you can mount it using the Connect button. Mount commands for Windows, Linux, and macOS are displayed. Note that for the SMB protocol, you can’t connect unless outgoing port 445 is open.
Table
Table storage is a NoSQL key-value storage service for storing semi-structured data. It provides fast access to large amounts of data.
For example, it’s used to store and consume user attribute information or device information in formats such as JSON, XML, or YAML (semi-structured data). Besides table storage, Azure Cosmos DB is another representative NoSQL service.
What is NoSQL (Not only SQL)?
It’s a term that represents a classification of databases, meaning it’s not a relational database = not a database where tables in tabular format are related.
Queue
Queue storage is a messaging service used for asynchronous communication between components. Have you heard of the following terms?
- Tight Coupling
- Loose Coupling
Roughly speaking, these terms represent whether the connections between multiple servers or functions are strong/weak, dependent/independent.
In the case of tightly coupled applications, the failure of one server, a bug in one function, or a bottleneck (delay) in one place can affect the entire system, and it becomes difficult to resolve these problems.
Messaging services are used to solve such problems. By using queue storage as an intermediary, servers and functions are designed to be loosely coupled.
For example, in a Web application that accepts large data uploads from users, if it’s designed to wait for the response to the request until the data is completely stored in memory (synchronous processing), it can cause response times to deteriorate.
In such cases, information about the data storage process is stored as a message in the queue, and a response is returned to the user without waiting for the data storage to complete (asynchronous processing).
In reality, there are considerations such as what to do if the data store fails, but this is the general idea. Queue is used to create loosely coupled applications.
Storage Access Tiers
Access tiers are options for optimizing cost and determining performance based on the frequency of access and retention of the data being stored.
These can be set for both blob and file, but the settings are slightly different. For AZ-900 exam preparation, it’s especially important to understand the blob access tiers.
Blob Access Tiers
There are four Access tiers for blob data:
| Type | Usage |
|---|---|
| Hot | For frequently accessed data High storage cost, low read/write cost |
| Cool | For infrequently accessed data stored for at least 30 days Lower storage cost than Hot, higher read/write cost |
| Cold new | For rarely accessed data stored for at least 90 days Lower storage cost than Cool, higher read/write cost |
| Archive | For rarely accessed data stored for at least 180 days Lowest storage cost, highest read/write cost |
※Azure Blob Storage Cold Tier was added in August 2023 (GA)
Cool / Cold / Archive have an early deletion period of “at least xx days”, and if you move the access tier or delete before this period, an early deletion penalty will be applied.
Hot / Cool / Cold are categorized as “online tiers” and can be accessed at any time, but Archive is an “offline tier” and cannot be read or modified.
To access data stored in Archive, you need to change it to either Hot / Cool / Cold, which can take several hours.
This process is called “rehydration“. Rehydration is a term that refers to adding water to dried food to restore it or replenishing fluids to treat dehydration.
This is a process required to restore data stored in the archive tier online, and there are two methods:
- Copy the file (blob) to an online tier
- Change the access tier to Hot or Cool or Cold
Rehydration can take several hours. The Archive tier is appropriate for long-term storage of data that can tolerate this rehydration time (such as audit logs).
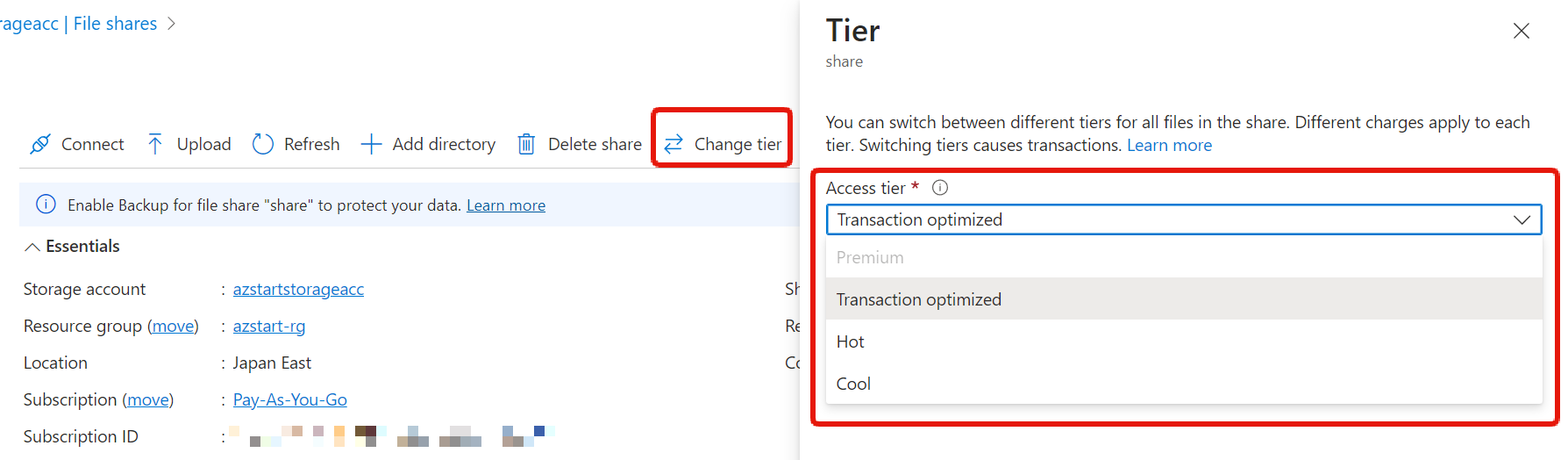
File Access Tiers
There are four File access tiers :
| Type | Usage |
|---|---|
| Premium | For systems requiring low latency Highest storage cost, free read/write cost |
| Transaction optimized | For systems with high transaction loads High storage cost, low read/write cost |
| Hot | For general scenarios like team sharing Medium storage cost, medium read/write cost |
| Cool | For long-term storage scenarios Low storage cost, highest read/write cost |
Premium is provided on SSD, while others are on HDD.
And as the name suggests, Premium can only be selected if the storage account performance is Premium.
Storage Redundancy Options
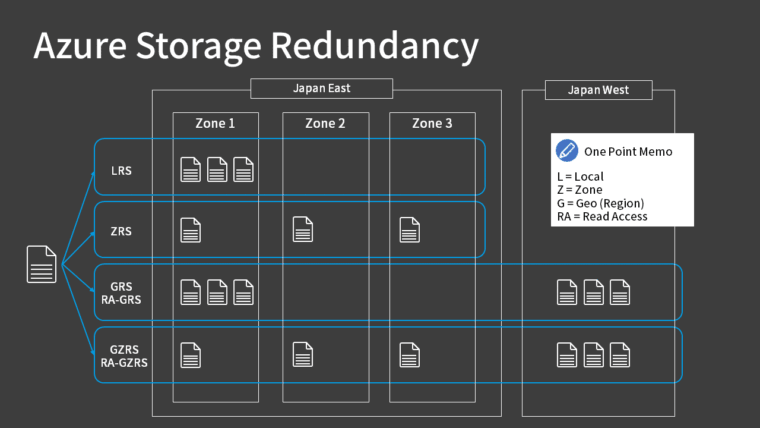
Storage accounts have six redundancy options to protect against data center and region failures. By default, at least 3 copies are stored, and as redundancy increases, so does the cost.
- LRS
- ZRS
- GRS
- RA-GRS
- GZRS
- RA-GZRS
The letters at the end of each term, RS, stand for “Redundant Storage,” so it is the initial letters L and Z that are important, indicating geography (location).
Here’s an overview diagram. It shows the primary region as Japan East and the secondary region as Japan West.
If you’re not familiar with terms like region pairs or availability zones, I recommend that you read this article first.

Locally Redundant Storage (LRS)
Stores 3 copies within the same region and the same data center. It can’t withstand data center or region failures, but it’s the most cost-effective option.
*For simplicity, we’ll explain here considering one zone as a single data center.
Zone-Redundant Storage (ZRS)
Stores 3 copies across separate data centers (availability zones) within the same region. It can’t withstand region failures, but because the zones are separate, it can withstand data center failures.
Geo-Redundant Storage (GRS)
Stores 3 copies in a single data center in the primary region, plus 3 copies in a single data center in the secondary region, for a total of 6 copies.
Additionally, if the redundancy option has RA prefixed, it’s called “Read-Access Geo-Redundant Storage (RA-GRS)“, which allows read access to the data stored in the secondary region.
In case of either data center or region failure, you can failover to access the data in the secondary region.
Whether read access is possible or not is more about distributing access rather than fault tolerance, which is used when you want to distribute read access from the primary region to the secondary region.
Geo-Zone-Redundant Storage (GZRS)
This is a form where the primary region side of GRS is changed from a single data center to separate data centers (availability zones).
If prefixed with RA, it’s called “Read-Access Geo-Zone-Redundant Storage (RA-GZRS)“.
These are the six redundancy options. I don’t think it’s that difficult once you understand the naming rules.
Since RA (read access) is an option when geo-redundant (G) is selected, you could say that LRS/ZRS/GRS/GZRS are essentially the four redundancy options for fault tolerance.
Key Points:
Copies to the primary region are written synchronously. Copies to the secondary region are written asynchronously. While there is no defined SLA for the asynchronous copy interval, it’s typically less than 15 minutes. It is important to understand that there may be temporary differences between primary and secondary.
Summary
In this article, we explained the storage services provided by Azure.
As a service for storing data, it’s an important service that you’ll almost certainly use. Let’s deepen our understanding of each option that affects performance, cost, and fault tolerance, after grasping the overview of Blob/File/Table/Queue.






